Wachstum ist in der Softwareentwicklung ein zweischneidiges Schwert. Mit dem Funktionsumfang von NoteLog stieg unweigerlich auch die architektonische Komplexität und damit die Schwierigkeit, bei Reviews den Überblick zu behalten. Ein konkretes Performance-Problem bei den Ladezeiten der »Spaces« verdeutlichte kürzlich das Kernproblem: Bisherige Cloud-Workflows stoßen an ihre Grenzen.
Wo ich früher auf die Kontextgröße von Antigravity vertrauen konnte, machen restriktive Token-Limits eine ganzheitliche Analyse mittlerweile unmöglich. Um die gewohnt hohen Standards an Architektur und UX zu halten, war es Zeit, den Analyse-Prozess grundlegend neu zu denken und lokal zu skalieren.

Lokale KI als Schlüssel
Strenge Grenzen bei der Benutzung von KI sind nicht nur ein Problem von Gemini, sondern betreffen nahezu alle Anbieter. Die gigantischen Rechenzentren möchten schließlich bezahlt werden, und kaum ein Unternehmen kann es sich leisten, Unsummen von Geld zu verbrennen.
Doch braucht es wirklich ein cloudbasiertes LLM für eine umfassende Analyse meines Projekts? Diese Aufgabe muss nicht schnell erledigt werden, sie kann bequem automatisiert nachts geschehen, wenn ich meinen Laptop nicht benötige. Auch muss die KI nicht lernfähig sein, es geht darum, Aspekte in der bestehenden Codebase zu analysieren und zu dokumentieren. Es ist also Zeit, sich mit lokalen LLMs zu beschäftigen.
Das Set-up
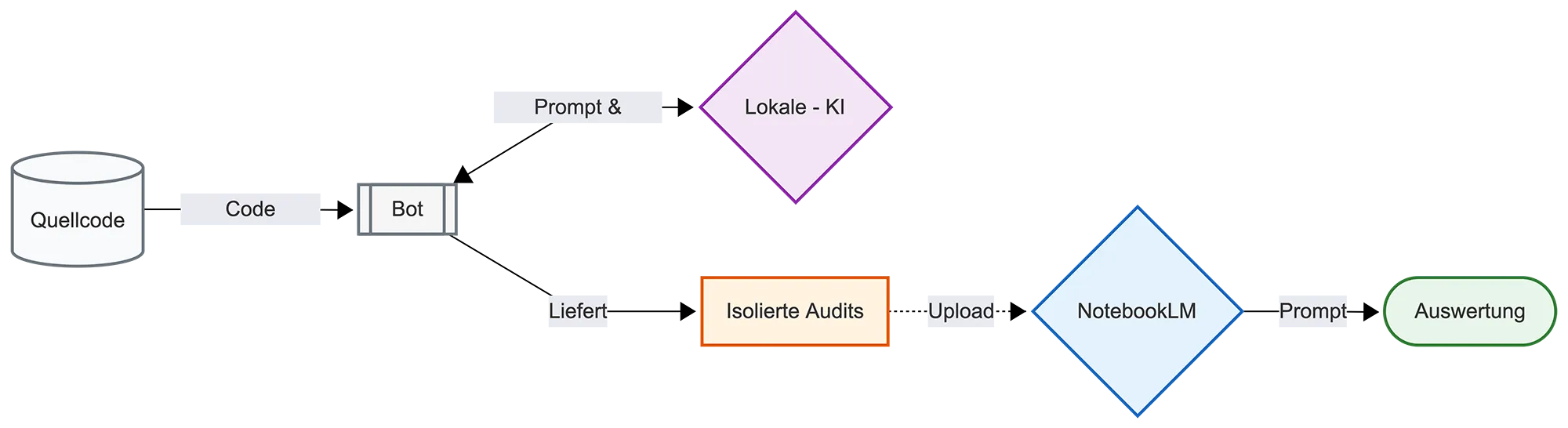
Damit ein lokales LLM bei mir laufen kann, benötige ich einerseits eine leistungsfähige Hardware, sowie eine Handvoll Tools. Ich entscheide mich schließlich für eine hybride Lösung. Die Analyse und Dokumentation der einzelnen Komponenten meiner Codebase erfolgt lokal, die übergreifende Auswertung dann mit NotebookLM. Ich nutze also das Beste aus zwei Welten.
Meine Hardware
Ich hatte mir im Herbst 2024 ein MacBook Pro mit M3-Pro-Chip und 36 GB RAM gekauft. Bis vor ein paar Wochen war mein MacBook meistens von dem gelangweilt, was es zu tun bekam. Ein wenig Figma, Xcode und Photoshop, nichts, was wirklich eine Herausforderung gewesen wäre. Als im Zuge der Entwicklung von NoteLog dann die Docker-App auf meinem Rechner landete, konnte ich das erste Mal die Leistungsreserven annähernd nutzen.
Für das Benutzen eines lokalen KI-Modells bietet mein MacBook nicht die idealen Voraussetzungen, aber eine gute Basis.
Die lokale KI-Engine
Als Erstes benötige ich eine Laufzeitumgebung für KI-Modelle. Diese fungiert als lokaler Server, lädt die Dateien der KI in den Arbeitsspeicher und bereitet sie für Berechnungen vor. Gleichzeitig stellt sie eine lokale Schnittstelle bereit, damit die KI angesprochen werden kann. Ich habe mich für Ollama entschieden, da die Installation extrem einfach ist und es für meine Hardware optimiert wurde. Zudem lässt es sich leicht mit Python-Skripten ansteuern.
Das KI-Modell
Nachdem ich die nötige Laufzeitumgebung eingerichtet habe, suche ich ein passendes KI-Modell für meinen Anwendungsfall. Es gibt eine Vielzahl an Modellen, mit jeweils individuellen Stärken und Schwächen. Zusätzlich bieten viele Modelle noch spezialisierte Varianten, z. B. für programmierlastige Aufgaben, an. Nach einiger Recherche und Ausprobieren lande ich schließlich bei Qwen 2.5 Coder 32B. Die Größe von 32 Milliarden Parametern passt optimal zu meinen 36 GB RAM und es gilt als aktueller Benchmark für komplexe Logik-Analysen.
Die Automatisierungs-Schicht
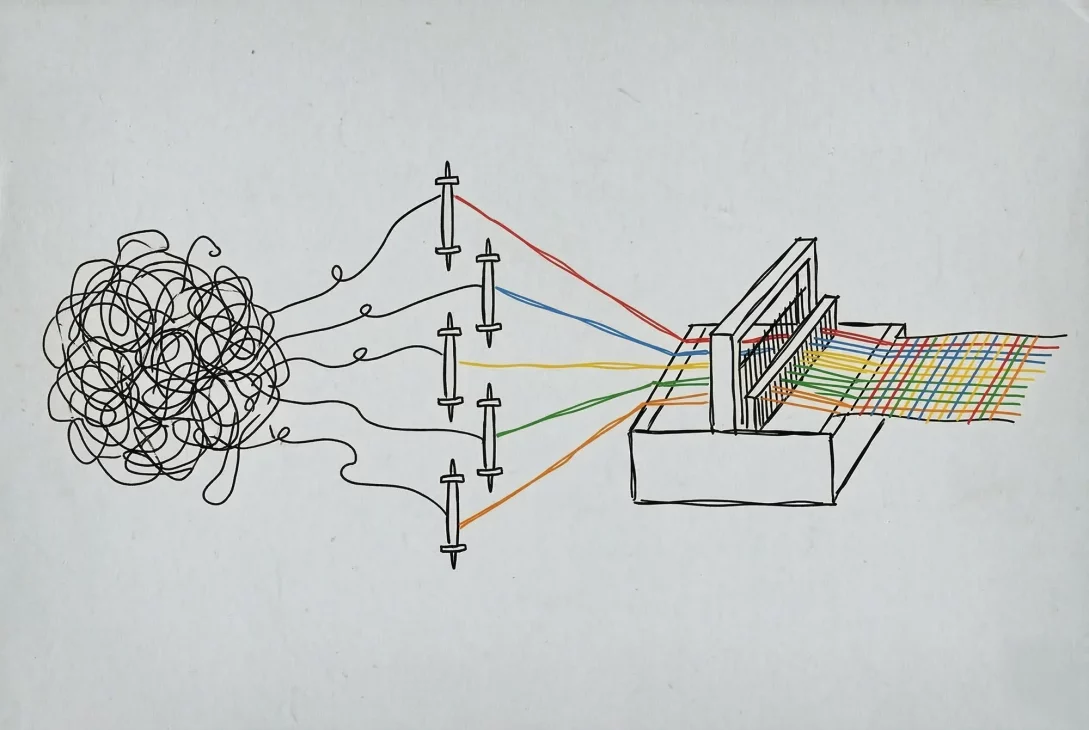
Damit das Audit meiner Codebase automatisiert vonstattengeht, benötige ich eine Automatisierungs-Schicht. Diese besteht aus mehreren schlanken Python-Skripten (den Bots). Diese fungieren als Dirigenten. Sie iterieren systematisch durch meine Projektstruktur, filtern unwichtigen Ballast wie .git- oder build-Ordner heraus und verpacken den reinen Quellcode zusammen mit einem passgenauen System-Prompt. Dieses Paket schicken sie an die Ollama-API und speichern die Antworten sauber strukturiert als Markdown-Dateien.
Die Synthese-Zentrale
Die lokale Code-Analyse hat jedoch einen Haken: Sie betrachtet jeden Ordner isoliert. Dadurch bleibt unbemerkt, wenn zwei völlig verschiedene Widgets redundante API-Calls abfeuern. Hier kommt NotebookLM ins Spiel. Als KI-gestützter Workspace dient es mir als Synthese-Zentrale. Ich lade alle lokal generierten Markdown-Berichte in NotebookLM hoch und kann mir anschließend eine umfassende Analyse zusammenstellen lassen. Auch detaillierte Rückfragen sind möglich, je nachdem, wie viele Informationen die einzelnen Markdown-Berichte enthalten.
Die Audit-Bots
1. Die UI-Polizei
Dieser Bot scannt das Flutter-Frontend auf hartcodierte Werte. Er identifiziert Farben (Hex-Codes), Abstände (Paddings, Margins) und Typografie-Definitionen, die nicht über das globale Theme oder zentrale Design-Tokens referenziert werden. Da NoteLog auf ein konsistentes Design-System setzt, stellt dieser Bot sicher, dass Design-Anpassungen zentral durchgeführt werden können und die Wartbarkeit der UI-Komponenten erhalten bleibt.
2. Der Backend Tech-Auditor
3. Der Business-Logic Bot
Dieser Bot dient dazu, die Übereinstimmung zwischen technischer Umsetzung und fachlichen Anforderungen zu verifizieren. Er extrahiert Kern-Entitäten, Use Cases und fachliche Invarianten aus dem Code, während technische Details wie Routing oder Datenbank-Konfigurationen ignoriert werden. Das Ergebnis ist eine rein funktionale Dokumentation, mit der sich prüfen lässt, ob das System die definierten Produktziele korrekt abbildet.
4. Der Frontend Deep-Digger
5. Der Datenfluss-Kartograph
Fazit: Effizienz durch methodische Trennung
Dieser Workflow verändert die Art und Weise, wie ich KI in der Entwicklung einsetze. Indem ich die Analyse strikt von der Fehlerbehebung trenne, nutze ich die jeweiligen Stärken der Tools optimal aus. Die lokalen Bots liefern die notwendige Tiefe ohne zusätzliche API-Kosten, NotebookLM stellt den projektweiten Kontext her und Cloud-Assistenten wie Antigravity oder Claude Code können sich auf die präzise Umsetzung konzentrieren. Da die Problemstellung bereits exakt definiert ist, reduziert sich die benötigte Kontextmenge drastisch, was nicht nur Token spart, sondern auch die Fehlerquote bei den Code-Änderungen senkt. Für ein wachsendes Projekt wie NoteLog ist dies ein effizienter Weg, um hohe Architektur- und Qualitätsstandards bei voller Kostenkontrolle beizubehalten.
Artikel teilen
Last modified: März 17, 2026
